近日,英特尔发布了第二代神经形态芯片Loihi,面积为31mm²,最多可封装100万个人工神经元,而上一代面积为60mm²,支持13.1万个神经元。同时,Loihi 2比上一代快10倍,资源密度提高了15倍,且能效更高。

Loihi 2有128个神经形态核心,相较于第一代,每个核心都有此前数量8倍的神经元和突触,这些神经元通过1.2亿个突触相互连接。据英特尔的早期评估,与在第一代Loihi上运行的标准深度网络相比,在准确性没有降低的情况下,Loihi 2上每次推理运算的次数减少到原来的至少60分之一。

英特尔神经形态计算实验室总监Mike Davies表示:“第二代芯片极大地提高了神经形态处理的速度、可编程性和容量,扩大了在功耗和时延受限的智能计算应用上的用途。英特尔正在开源Lava,以满足在实践中对软件融合、基准测试和跨平台合作的需求,并加快商业可行性的进程。”
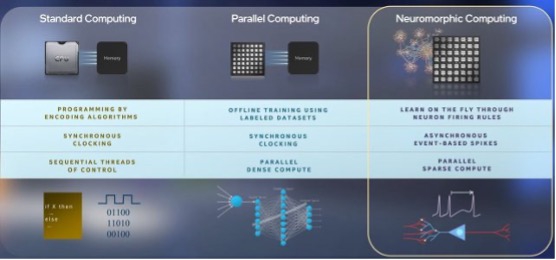
Davies认为,Loihi 2等芯片擅长于处理赋予计算机感官(例如视觉和嗅觉)的任务。因为效率很高,神经形态芯片非常适合电源有限且不受传统计算机网络束缚的移动设备。
为什么需要神经形态芯片?
在曾经很长一段时间内,规则式(rule-based)方法都在人工智能领域占据主流,对计算机进行编程需要编写分步说明。以教计算机学会识别狗举例,这会涉及列出一组规则来指导其判断,如检查它是否有四只脚等等。但如果计算机遇到一只只有三只腿的小狗怎么办?这时也许就需要更多规则,但是列出无穷无尽的规则,并让计算机每次做出类型决策时都重复该过程是低效且不切实际的。
而人类的学习方式则与此相异,在区分狗与猫时无需被告知任何相关规则,于是学习人类大脑的运行方式成为人工智能发展的一个重要方向。
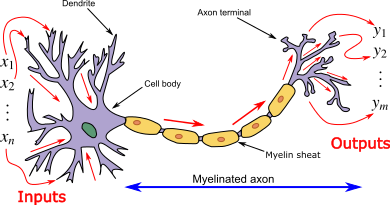
20世纪40年代,科学家们开始用数学方法对神经元进行建模,此后则开始用计算机对神经元网络进行建模。人工神经元和突触比大脑中的要简单得多,但它们的运作原理相同——大脑中的神经元通过跨突触相互发送尖峰信号(Spiking Signals)来进行交流。
许多简单的单元(“神经元”)连接到许多其他单元(通过“突触”),一个神经元接收来自许多其他神经元的信号,当刺激达到某个阈值时,它会将自己的信号发送给周围的神经元,大脑则通过调整神经元之间的连接强度来学习。
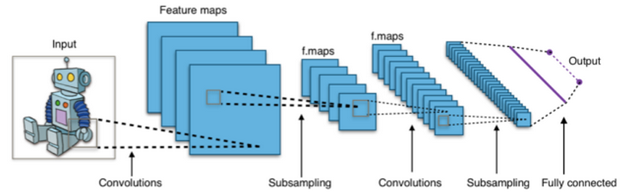
人工神经网络(Artificial Neural Networks)通常由层组成,具有许多此类层的网络称为深度学习网络。神经网络是机器学习的一种形式,是计算机根据经验调整其行为的过程,在今天用于自动驾驶、人脸识别等领域。
康奈尔大学的神经生物学家Thomas Cleland曾说,神经形态计算(Neuromorphic Computing)“将成为摇滚明星”,“它不会把一切都做得更好,但它将完全拥有计算领域的一小部分”。
然而模仿大脑的计算成本非常高,人脑有数十亿个神经元和数万亿个突触,即使模拟一小块大脑也可能需要对每块输入进行数百万次计算。运行所有这些小计算并不适合必须一次处理一条指令的经典计算架构(CPU),而今天常用的图形处理单元(GPU)仍然没有像大脑那样有效地执行深度学习——人类的大脑可以一边驾驶汽车,一边谈论自动驾驶的未来,但使用的瓦数比灯泡还少。

常规计算机架构与神经形态架构的对比
于是,解决神经形态计算问题的芯片出现了。最初是在20世纪80年代,工程师Carver Mead创造了术语“神经形态处理器”(neuromorphic processors)来描述以基于大脑的松散方式运行的计算机芯片,为这个领域奠定了基础。
神经形态芯片如何运行?
Loihi芯片包含通过通信网络连接的128个独立内核,每个独立内核中都有大量单独的“神经元”或执行单元,每一个神经元都可以接收来自任何其他神经元脉冲形式的输入——同一核心中的邻居、同一芯片上不同核心中的一个单元或完全来自另一个芯片。随着时间的推移,神经元会整合它接收到的尖峰信号(Spiking Signals,神经元通过跨突触相互发送尖峰信号进行交流),并根据其编程的行为来确定何时将自己的尖峰信号发送到与其连接的任何神经元。
所有尖峰信号都是异步发生的。在设定的时间间隔内,同一芯片上的嵌入式x86内核会强制同步。届时,神经元将重新计算其各种连接的权重——本质上,是决定对所有向其发送信号的单个神经元给予多少关注。
具体运行过程是,芯片上的部分执行单元充当树突,部分基于从过去行为得出的权重处理来自通信网络的传入信号,以确定活动何时超过临界阈值,并在超过时触发其自身的峰值。然后执行单元的“轴突”查找它与哪些其他执行单元进行通信,并向每个执行单元发送一个尖峰信号。
与普通处理器不同,神经形态芯片没有外部RAM(Random-access memory,随机存储器),而是每个神经元都有自己专用的小型内存,这包括它分配给来自不同神经元的输入的权重,最近活动的缓存,以及发送尖峰信号的所有其他神经元的列表。
神经形态芯片与传统处理器间的另一大区别则是能效。IBM于2014年推出的TrueNorth芯片,使用的功率还不到在传统处理器上模拟尖峰神经网络所需的0.0001%。英特尔神经拟态计算实验室主任Mike Davies 表示,Loihi在某些特定工作负载上可以比传统处理器高2,000倍。
最新的Loihi 2取得了什么样的新进展?
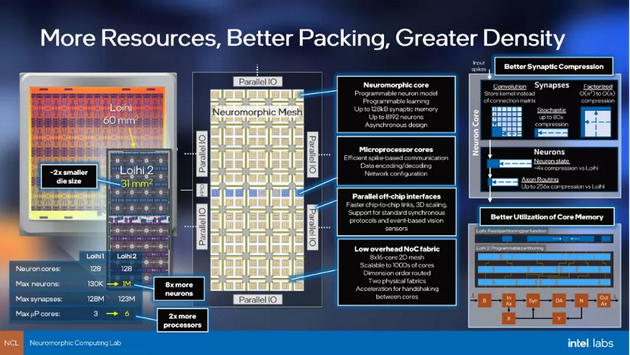
Loihi 2使用了更先进的制造工艺——英特尔第一个EUV工艺节点Intel 4,现在每个内核只需要原来所需空间的一半。同时,Loihi 2不仅能够通过二维连接网格进行芯片间的通信,还可以在三维尺度上进行通信,从而大大增加了能处理的神经元总数。每个芯片的嵌入式处理器数量从三个增加到六个,每个芯片的神经元数量增加了八倍。
同时,英特尔表示,它已经通过并优化了所有异步硬件,使 Loihi 2在更新神经元状态时的性能提高了一倍,并将尖峰生成的性能提高了十倍。
另一个主要变化是处理器评估神经元状态以确定是否发送尖峰信号的部分。在原始处理器中,用户可以执行一些简单的数学运算来做出决定。在Loihi 2中,则可以访问简化的可编程管道,执行比较和控制指令流。据科技媒体《Ars》表示,Davies在接受其采访时表示,“你可以将这些程序指定到每个神经元级别,这意味着两个相邻的神经元可以运行完全不同的程序。”
不仅如此,“每个神经元处理其内部记忆的方式也更加灵活——会有一个固定分配和一个可以更动态划分的内存池。”
与Loihi2同时推出的开源软件框架——Lava
虽然尖峰神经网络(spiking neural networks)可以非常有效地解决很多问题,但目前的一个困难在于,这是一种非常不同的编程类型,需要以同样不同的方式思考算法开发,要怎样找到了解如何使用的人?Davies表示,目前精通它的大多数人都来自理论神经生物学背景。
到目前为止,这意味着英特尔主要将Loihi推向了研究社区,这限制了其市场销售范围。
从长远来看,英特尔希望看到Loihi衍生品最终出现在更广泛的系统中,从充当嵌入式系统中的协处理器到数据中心的大型Loihi集群。那么,英特尔就需要很容易找到可以为其编程的人。
为此,英特尔将Loihi 2的发布与Lava的开源软件框架的发布结合起来。“Lava旨在帮助神经形态编程传播到更广泛的计算机科学界,”Davies在接受外媒采访时表示。