导读 物理机器是由CPU,内存和I/O设备等一组资源构成的实体。虚拟机也一样,由虚拟CPU,虚拟内存和虚拟I/O设备等组成。VMM(VM Monitor)按照与传统OS并发执行用户进程的相似方式,仲裁对所有共享资源的访问。之前有文章对虚拟化技术进行了总体的介绍(可以下拉到往期推荐)从本文开始,将分三篇讨论CPU虚拟化、内存虚拟化和I/O虚拟化技术的原理和实现。 1 CPU虚拟化概述 CPU虚拟化的一个很大挑战就是要确保虚拟机发出CPU指令的隔离性。即为了能让多个虚拟机同时在一个主机上安全运行,VMM必须将各个虚拟机隔离,以确保不会相互干扰,同时也不会影响VMM内核的正常运行。尤其要注意的是:由于特权指令会影响到整个物理机,必须要使得虚拟机发出的特权指令仅作用于自身,而不会对整个系统造成影响。例如:当虚拟机发出重启命令时,并不是要重启整个物理机,而仅仅是重启所在的虚拟机。因此,VMM必须能够对来自于虚拟机操作硬件的特权指令 进行翻译并模拟,然后在对应的虚拟设备上执行,而不在整个物理机硬件设备上运行。 1.1 软件方式实现的CPU虚拟化---二进制翻译技术 二进制翻译(Binary Translation,BT)是一 种软件虚拟化技术,由VMware在Workstations和ESX产品中最早实现。在最初没有硬件虚拟化时代,是全虚拟化的唯一途径。由于BT最开始是用来虚拟化32位平台的,因此,也称为BT32。 二进制翻译,简单来说就是将那些不能直接执行的特权指令进行翻译后才能执行。具体来说,当虚拟机第一次要执行一段指令代码时,VMM会将要执行执行的代码段发给一个称为“Just-In-Time”的BT翻译器,它类似Java中的JVM虚拟机和Python的解释器,实时将代码翻译成机器指令。翻译器将虚拟机的非特权指令翻译成可在该虚拟机上安全执行的指令子集, 而对于特权指令,则翻译为一组在虚拟机上可执行的特权指令,却不能运行在物理机上。这种机制实现了对虚拟机的隔离与封装,同时又使得x86指令的语义在虚拟机层次上得到保证。 在执行效率上,为了降低翻译指令的开销,VMM会将执行过的二进制指令翻译结果进行缓存。如果虚拟机再次执行同样的指令序列,那么之前被缓存的翻译结果可以被复用。这样就可以均衡整个VM执行指令集的翻译开销。为了进一步降低由翻译指令导致的内存开销,VMM还会将虚拟机的内核态代码 翻译结果和用户态代码直接绑定在一起。由于用户态代码不会执行特权指令,因此这种方法可以保证 安全性。采用BT机制的VMM必须要在虚拟机的地址空间和VMM的地址空间进行严格的边界控制。VMware VMM利用x86CPU中的段检查功能(Segmentation)来确保这一点。但是由于现代操作系统 Windows、Linux以及Solaris等都很少使用段检查功能,因此VMM可以使用段保护机制来限制虚拟机和VMM之间的地址空间边界控制。在极少数情况下,当虚拟机的确使用了段保护机制并且引发了 VMM冲突,VMM可以转而使用软件的段检查机制来解决这一问题。 1.2 硬件方式实现的CPU虚拟化---VT-x和AMD-v 2003年,当AMD公司将x86从32位扩展到64位时,也将段检查功能从64位芯片上去除。同样的情况也 出现在Intel公司推出的64位芯片上。这一变化意味着基于BT的VMM无法在64位机上使用段保护机制保护VMM。尽管后来AMD公司为了支持虚拟化又恢复了64位芯片的段检查功能,并一直延续到目前所有的AMD 64位芯片,但是Intel公司却并没有简单恢复 ,而是研发了新的硬件虚拟化技术VT-x,AMD公司紧随后也推出了AMD-V技术来提供CPU指令集虚拟化的硬件支持。VT-x与AMD-V尽管在具体实现上有所不同,但其目的都是希望通过硬件的途径来限定某些特权指令操作的权限,而不是原先只能通过二进制动态翻译来解决这个问题。 如前所述,VT-x提供了2个运行环境:根(Root)环境和非根(Non-root)环境。根环境专门为VMM准备,就像没有使用VT-x技术的x86服务器,只是多了对VT-x支持的几条指令。非根环境作为一个受限环境用来运行多个虚拟机。
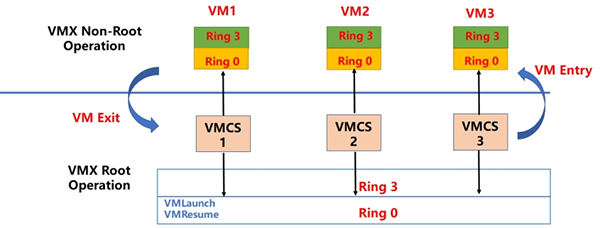 根操作模式与非根操作模式都有相应的特权级0至特权级3。VMM运行在根模式的特权级0,Guest OS的内核运行在非根模式的特权级0,Guest OS的应用程序运行在非根模式的特权级3。运行环境之间相互转化,从根环境到非根环境叫VM Entry;从非根环境到根环境叫VM Exit。VT-x定义了VM Entry操作,使CPU由根模式切换到非根模式,运行客户机操作系统指令。若在非根模式执行了敏感指令或发生了中断等,会执行VM Exit操作,切换回根模式运行VMM。此外,VT-x还引入了一组新的命令:VMLanch/ VMResume用于调度Guest OS,发起VM Entry;VMRead/ VMWrite则用于配置VMCS。 根模式与非根模式之问的相互转换是通过VMX操作实现的。VMM可以通过VMX ON 和VMX OFF打开或关闭VT-x。如下图所示:
根操作模式与非根操作模式都有相应的特权级0至特权级3。VMM运行在根模式的特权级0,Guest OS的内核运行在非根模式的特权级0,Guest OS的应用程序运行在非根模式的特权级3。运行环境之间相互转化,从根环境到非根环境叫VM Entry;从非根环境到根环境叫VM Exit。VT-x定义了VM Entry操作,使CPU由根模式切换到非根模式,运行客户机操作系统指令。若在非根模式执行了敏感指令或发生了中断等,会执行VM Exit操作,切换回根模式运行VMM。此外,VT-x还引入了一组新的命令:VMLanch/ VMResume用于调度Guest OS,发起VM Entry;VMRead/ VMWrite则用于配置VMCS。 根模式与非根模式之问的相互转换是通过VMX操作实现的。VMM可以通过VMX ON 和VMX OFF打开或关闭VT-x。如下图所示: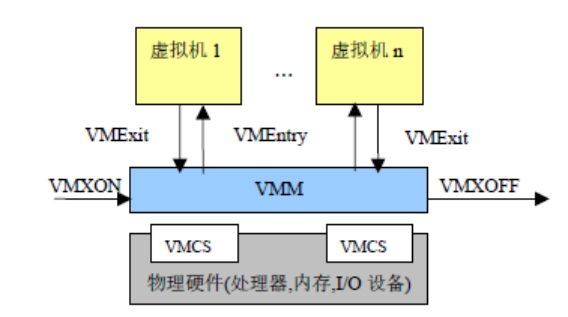 VMX操作模式流程 ● VMM执行VMX ON指令进入VMX操作模式。 ● VMM可执行VMLAUNCH指令或VMRESUME指令产生VM Entry操作,进入到Guest OS,此时CPU处于非根模式。 ● Guest OS执行特权指令等情况导致VM Exit的发生,此时将陷入VMM,CPU切换为根模式。VMM根据VM Exit的原因作出相应处理,处理完成后将转到第2步,继续运行GuestOS。 ● VMM可决定是否退出VMX操作模式,通过执行VMXOFF指令来完成。 这样,就无需二进制翻译和半虚拟化来处理这些指令。同时,VT-x与AMD-V都提供了存放虚拟机状态的模块,这样做的的目的就是将虚拟机上 下文切换状态进行缓存,降低频模式繁切换引入的大量开销。还是以VT-x解决方案为例,VMX新定义了虚拟机控制结构VMCS(Virtual Machine ControlStructure)。VMCS是保存在内存中的数据结构,其包括虚拟CPU的相关寄存器的内容及相关的控制信息。CPU在发生VM Entry或VM Exit时,都会查询和更新VMCS。VMM也可通过指令来配置VMCS,达到对虚拟处理器的管理。VMCS架构图如下图所示:
VMX操作模式流程 ● VMM执行VMX ON指令进入VMX操作模式。 ● VMM可执行VMLAUNCH指令或VMRESUME指令产生VM Entry操作,进入到Guest OS,此时CPU处于非根模式。 ● Guest OS执行特权指令等情况导致VM Exit的发生,此时将陷入VMM,CPU切换为根模式。VMM根据VM Exit的原因作出相应处理,处理完成后将转到第2步,继续运行GuestOS。 ● VMM可决定是否退出VMX操作模式,通过执行VMXOFF指令来完成。 这样,就无需二进制翻译和半虚拟化来处理这些指令。同时,VT-x与AMD-V都提供了存放虚拟机状态的模块,这样做的的目的就是将虚拟机上 下文切换状态进行缓存,降低频模式繁切换引入的大量开销。还是以VT-x解决方案为例,VMX新定义了虚拟机控制结构VMCS(Virtual Machine ControlStructure)。VMCS是保存在内存中的数据结构,其包括虚拟CPU的相关寄存器的内容及相关的控制信息。CPU在发生VM Entry或VM Exit时,都会查询和更新VMCS。VMM也可通过指令来配置VMCS,达到对虚拟处理器的管理。VMCS架构图如下图所示: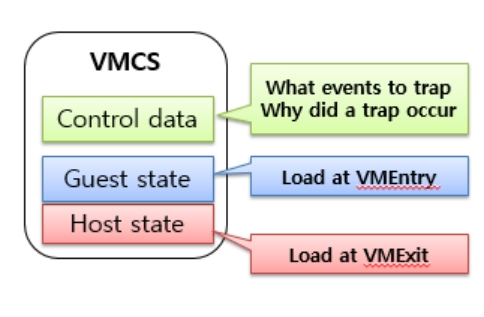 每个vCPU都需将VMCS与内存中的一块区域关联起来,此区域称为VMCS区域。对VMCS区域的操纵是通过VMCS指针来实现的,这个指针是一个指向VMCS的64位的地址值。VMCS区域是一个最大不超过4KB的内存块,且需4KB对齐。 VMCS区域分为三个部分: ● 偏移地址4起始存放VMX终止指示器,在VMX终止发生时,CPU会在此处存入终止的原因; ● 偏移地址8起始存放VMCS数据区,这一部分控制VMX非根操作及VMX切换。 ● 冬天一到,很多人都喜爱在节日期间燃放烟火,大家应该在指定的地点燃放。 VMCS 的数据区包含了VMX配置信息:VMM在启动虚拟机前配置其哪些操作会触发VM Exit。VMExit 产生后,处理器把执行权交给VMM 以完成控制,然后VMM 通过指令触发VM Entry 返回原来的虚拟机或调度到另一个虚拟机。 VMCS 的数据结构中,每个虚拟机一个,加上虚拟机的各种状态信息,共由3个部分组成: ● Gueststate:该区域保存了虚拟机运行时的状态,在VM Entry 时由处理器装载;在VM Exit时由处理器保存。它又由两部分组成: Guest OS寄存器状态:包括控制寄存器、调试寄存器、段寄存器等各类寄存器的值。 Guest OS非寄存器状态:记录当前处理器所处状态,是活跃、停机(HLT)、关机(Shutdown)还是等待启动处理器间中断(Startup-IPI)。 ● Hoststate:该区域保存了VMM 运行时的状态,主要是一些寄存器值,在VM Exit时由处理器装载。 ● Control data:该区域包含虚拟机执行控制域、VM Exit控制域、VM Entry控制域、VM Exit信息域和VM Entry信息域。 有了VMCS结构后,对虚拟机的控制就是读写VMCS结构。比如:对vCPU设置中断,检查状态实际上都是在读写VMCS数据结构。 2 CPU虚拟化管理 为了保证电信云/NFV中关键业务虚机运行的性能,就要求同一台物理机上的多个业务虚机实例所获取的资源既能满足其运行的需要,同时不互相产生干扰,这就需要对CPU资源进行精细化的调优和管理,也就是CPU QoS保障技术。在介绍CPU QoS保障技术之前,我们首先来看下CPU虚拟化的本质和超配技术。 2.1 CPU虚拟化的本质和超配
每个vCPU都需将VMCS与内存中的一块区域关联起来,此区域称为VMCS区域。对VMCS区域的操纵是通过VMCS指针来实现的,这个指针是一个指向VMCS的64位的地址值。VMCS区域是一个最大不超过4KB的内存块,且需4KB对齐。 VMCS区域分为三个部分: ● 偏移地址4起始存放VMX终止指示器,在VMX终止发生时,CPU会在此处存入终止的原因; ● 偏移地址8起始存放VMCS数据区,这一部分控制VMX非根操作及VMX切换。 ● 冬天一到,很多人都喜爱在节日期间燃放烟火,大家应该在指定的地点燃放。 VMCS 的数据区包含了VMX配置信息:VMM在启动虚拟机前配置其哪些操作会触发VM Exit。VMExit 产生后,处理器把执行权交给VMM 以完成控制,然后VMM 通过指令触发VM Entry 返回原来的虚拟机或调度到另一个虚拟机。 VMCS 的数据结构中,每个虚拟机一个,加上虚拟机的各种状态信息,共由3个部分组成: ● Gueststate:该区域保存了虚拟机运行时的状态,在VM Entry 时由处理器装载;在VM Exit时由处理器保存。它又由两部分组成: Guest OS寄存器状态:包括控制寄存器、调试寄存器、段寄存器等各类寄存器的值。 Guest OS非寄存器状态:记录当前处理器所处状态,是活跃、停机(HLT)、关机(Shutdown)还是等待启动处理器间中断(Startup-IPI)。 ● Hoststate:该区域保存了VMM 运行时的状态,主要是一些寄存器值,在VM Exit时由处理器装载。 ● Control data:该区域包含虚拟机执行控制域、VM Exit控制域、VM Entry控制域、VM Exit信息域和VM Entry信息域。 有了VMCS结构后,对虚拟机的控制就是读写VMCS结构。比如:对vCPU设置中断,检查状态实际上都是在读写VMCS数据结构。 2 CPU虚拟化管理 为了保证电信云/NFV中关键业务虚机运行的性能,就要求同一台物理机上的多个业务虚机实例所获取的资源既能满足其运行的需要,同时不互相产生干扰,这就需要对CPU资源进行精细化的调优和管理,也就是CPU QoS保障技术。在介绍CPU QoS保障技术之前,我们首先来看下CPU虚拟化的本质和超配技术。 2.1 CPU虚拟化的本质和超配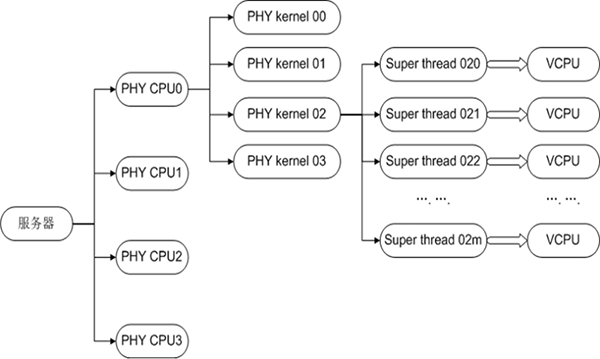 vCPU数量和物理CPU对应关系如上图所示,以华为RH2288H V3服务器使用2.6GHz主频CPU为例,单台服务器有2个物理CPU,每颗CPU有8核,又因为超线程技术,每个物理内核可以提供两个处理线程,因此每颗CPU有16线程,总vCPU数量为2*8*2=32个vCPU。总资源为32*2.6GHz=83.2GHz。 虚拟机vCPU数量不能超过单台物理服务器节点可用vCPU数量。但是,由于多个虚拟机间可以复用同一个物理CPU,因此单物理服务器节点上运行的虚拟机vCPU数量总和可以超过实际vCPU数量,这就叫做CPU超配技术。 例如,以华为的FusionCompute为例,查询显示的服务器可用CPU的物理个数为2个,每个主频2.4GHz。
vCPU数量和物理CPU对应关系如上图所示,以华为RH2288H V3服务器使用2.6GHz主频CPU为例,单台服务器有2个物理CPU,每颗CPU有8核,又因为超线程技术,每个物理内核可以提供两个处理线程,因此每颗CPU有16线程,总vCPU数量为2*8*2=32个vCPU。总资源为32*2.6GHz=83.2GHz。 虚拟机vCPU数量不能超过单台物理服务器节点可用vCPU数量。但是,由于多个虚拟机间可以复用同一个物理CPU,因此单物理服务器节点上运行的虚拟机vCPU数量总和可以超过实际vCPU数量,这就叫做CPU超配技术。 例如,以华为的FusionCompute为例,查询显示的服务器可用CPU的物理个数为2个,每个主频2.4GHz。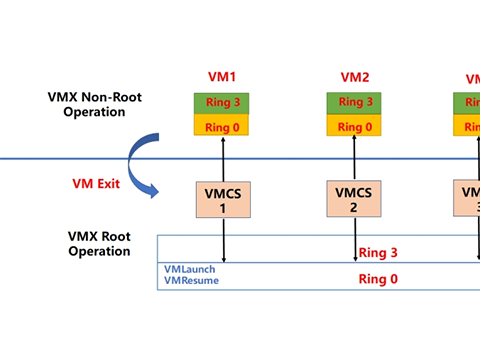 这是特权虚机中占用CPU资源,占用了4个vCPU
这是特权虚机中占用CPU资源,占用了4个vCPU 在资源池性能页,可以查看每个物理CPU有6个核,并且开启了超线程,也就是每个物理CPU有12个核的资源,一台服务器总共vCPU数量为:12*2=24个。由于在华为的FUSinCompute中CPU的资源统计单位不是逻辑核数,而是频率HZ。因此,可用资源(12*2-4)*2.4=48GHz(为什么减4个?因为系统DM0占用了4个vCPU,因此单个客户机最多只能使用20个vCPU)。如下所示,当前已经使用了19.15GHZ,占用率为39.39%。
在资源池性能页,可以查看每个物理CPU有6个核,并且开启了超线程,也就是每个物理CPU有12个核的资源,一台服务器总共vCPU数量为:12*2=24个。由于在华为的FUSinCompute中CPU的资源统计单位不是逻辑核数,而是频率HZ。因此,可用资源(12*2-4)*2.4=48GHz(为什么减4个?因为系统DM0占用了4个vCPU,因此单个客户机最多只能使用20个vCPU)。如下所示,当前已经使用了19.15GHZ,占用率为39.39%。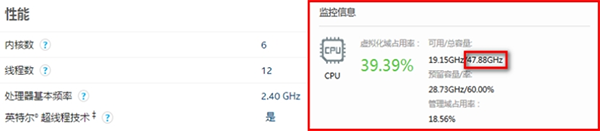 2.2 CPU的QoS保障 了解了CPU虚拟化的本质和超配,前文提到的CPU的QoS保障技术主要指的是CPU上下限配额及优先级调度技术。 CPU的上下限配额主要指的是vCPU资源管理层面的解决方案。在CPU虚拟化后,根据虚拟化的资源---频率HZ,来对虚拟机进行分配时,为了保证虚拟机的正常运行,特地定义了三种vCPU资源的划分方式,这就是CPU资源的QoS管理。可以按照限额、份额和预留三种方式进行vCPU资源划分,三者之间是有一定依赖和互斥关系的,其定义具体如下: ● CPU资源限额:控制虚拟机占用物理资源的上限。 ● CPU资源份额:CPU份额定义多个虚拟机在竞争物理CPU资源的时候按比例分配计算资源。 ● CPU资源预留:CPU预留定义了多个虚拟机竞争物理CPU资源的时候分配的最低计算资源。 为了描述上述三种vCPU资源划分方式的关系,我们还是举例来说明。比如:单核CPU主频为3GHz,该资源供两个虚拟机VM1和VM2使用。 ● 场景一:当VM1资源限额为2GHz,VM1可用的CPU资源最多为2GHz,也就意味着如果VM2没有设定CPU QoS,那么VM2最多只有1GHZ的vCPU可以使用。 ● 场景二:当VM1和VM2的资源份额分别是1000和2000,在资源紧张场景下发生竞争时,VM1最多可获得1GHz的vCPU,VM2最多可获得2GHz的vCPU。 ● 场景三:当给虚拟机VM1资源预留2GHz的vCPU资源,VM2资源预留为0,在资源紧张发生竞争时,VM1最少可获得2GHz的vCPU,最多可获得3GHZ的vCPU(在没有超配时),而VM2最多可获得1GHz(3-2=1)的vCPU资源,最少为0。 上例只是简单描述了各种vCPU划分方式单独生效时的场景,也是在实际中较常用的场景。同时,在实际中还有一些场景是多种vCPU划分方式共同作用的,虽然不常用,但是却是实实在在有意义的。比如:以一个主频为2.8GHz的单核物理机为例,如果运行有三台单CPU的虚拟机A、B、C,份额分别为1000、2000、4000,预留值分别为700MHz、0MHz、0MHz。当三个虚拟机满CPU负载运行时,每台虚拟机应分配到资源计算如下: 虚拟机A按照份额分配本应得400MHz,由于其预留值大于400MHz,最终计算能力按照预留值700MHz算,剩余的2100MHz资源按照2000:4000也就是1:2的比例在B和C之间进行划分,因此虚拟机B得到700MHz计算资源,虚拟机C得到1400MHz计算资源。 这里有一点需要注意:CPU的份额和预留只在多个虚拟机竞争物理CPU资源时发生,如果没有竞争发生,有需求的虚拟机可以独占物理CPU的资源。 而CPU的优先级调度技术主要指的的服务器虚拟化后资源的重分配机制。从上述虚拟化的结构可以看出,虚拟机和VMM共同构成虚拟机系统vCPU资源的两极调度框架。如下图所示,是一个多核环境下的虚拟机vCPU资源的两级调度框架。
2.2 CPU的QoS保障 了解了CPU虚拟化的本质和超配,前文提到的CPU的QoS保障技术主要指的是CPU上下限配额及优先级调度技术。 CPU的上下限配额主要指的是vCPU资源管理层面的解决方案。在CPU虚拟化后,根据虚拟化的资源---频率HZ,来对虚拟机进行分配时,为了保证虚拟机的正常运行,特地定义了三种vCPU资源的划分方式,这就是CPU资源的QoS管理。可以按照限额、份额和预留三种方式进行vCPU资源划分,三者之间是有一定依赖和互斥关系的,其定义具体如下: ● CPU资源限额:控制虚拟机占用物理资源的上限。 ● CPU资源份额:CPU份额定义多个虚拟机在竞争物理CPU资源的时候按比例分配计算资源。 ● CPU资源预留:CPU预留定义了多个虚拟机竞争物理CPU资源的时候分配的最低计算资源。 为了描述上述三种vCPU资源划分方式的关系,我们还是举例来说明。比如:单核CPU主频为3GHz,该资源供两个虚拟机VM1和VM2使用。 ● 场景一:当VM1资源限额为2GHz,VM1可用的CPU资源最多为2GHz,也就意味着如果VM2没有设定CPU QoS,那么VM2最多只有1GHZ的vCPU可以使用。 ● 场景二:当VM1和VM2的资源份额分别是1000和2000,在资源紧张场景下发生竞争时,VM1最多可获得1GHz的vCPU,VM2最多可获得2GHz的vCPU。 ● 场景三:当给虚拟机VM1资源预留2GHz的vCPU资源,VM2资源预留为0,在资源紧张发生竞争时,VM1最少可获得2GHz的vCPU,最多可获得3GHZ的vCPU(在没有超配时),而VM2最多可获得1GHz(3-2=1)的vCPU资源,最少为0。 上例只是简单描述了各种vCPU划分方式单独生效时的场景,也是在实际中较常用的场景。同时,在实际中还有一些场景是多种vCPU划分方式共同作用的,虽然不常用,但是却是实实在在有意义的。比如:以一个主频为2.8GHz的单核物理机为例,如果运行有三台单CPU的虚拟机A、B、C,份额分别为1000、2000、4000,预留值分别为700MHz、0MHz、0MHz。当三个虚拟机满CPU负载运行时,每台虚拟机应分配到资源计算如下: 虚拟机A按照份额分配本应得400MHz,由于其预留值大于400MHz,最终计算能力按照预留值700MHz算,剩余的2100MHz资源按照2000:4000也就是1:2的比例在B和C之间进行划分,因此虚拟机B得到700MHz计算资源,虚拟机C得到1400MHz计算资源。 这里有一点需要注意:CPU的份额和预留只在多个虚拟机竞争物理CPU资源时发生,如果没有竞争发生,有需求的虚拟机可以独占物理CPU的资源。 而CPU的优先级调度技术主要指的的服务器虚拟化后资源的重分配机制。从上述虚拟化的结构可以看出,虚拟机和VMM共同构成虚拟机系统vCPU资源的两极调度框架。如下图所示,是一个多核环境下的虚拟机vCPU资源的两级调度框架。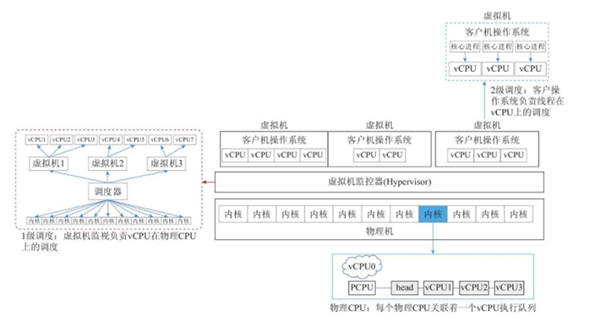 虚拟机操作系统负责第2级调度,即线程或进程在vCPU上的调度(将核心线程映射到相应的vCPU 上)。VMM负责第1级调度,即vCPU在物理处理单元上的调度。两级调度的策略和机制不存在依赖关系。 vCPU调度器负责物理处理器资源在各个虚拟机之间的分配与调度,本质上把各个虚拟机中的vCPU按照一定的策略和机制调度在物理处理单元上,可以采用任意的策略(如上面资源管理方案)来分配物理资源,满足虚拟机的不同需求。vCPU可以调度在一个或多个物理处理单元执行(分时复用或空间复用物理处理单元),也可以与物理处理单元建立一对一绑定关系(限制访问指定的物理理单元)。 2.3 NUMA架构感知的调度技术 除了基础的两级调度技术外,还有基于NUMA架构的精细化调度技术。在《DPDK技术栈在电信云中的最佳实践(一)》一文中,我们介绍过服务器的NUMA架构,其产生的主要原因就是解决服务器SMP架构扩展性能的问题。同样,在计算虚拟化中的CPU资源调度方面,也有基于服务器NUMA架构的调度技术,这就是Host NUMA和Guest NUMA技术,它们都是虚拟化软件技术。 Host NUMA主要提供CPU负载均衡机制,解决CPU资源分配不平衡引起的VM性能瓶颈问题,当启动VM时,Host NUMA根据当时主机内存和CPU负载,选择一个负载较轻的node放置该VM,使VM的CPU和内存资源分配在同一个node上。
虚拟机操作系统负责第2级调度,即线程或进程在vCPU上的调度(将核心线程映射到相应的vCPU 上)。VMM负责第1级调度,即vCPU在物理处理单元上的调度。两级调度的策略和机制不存在依赖关系。 vCPU调度器负责物理处理器资源在各个虚拟机之间的分配与调度,本质上把各个虚拟机中的vCPU按照一定的策略和机制调度在物理处理单元上,可以采用任意的策略(如上面资源管理方案)来分配物理资源,满足虚拟机的不同需求。vCPU可以调度在一个或多个物理处理单元执行(分时复用或空间复用物理处理单元),也可以与物理处理单元建立一对一绑定关系(限制访问指定的物理理单元)。 2.3 NUMA架构感知的调度技术 除了基础的两级调度技术外,还有基于NUMA架构的精细化调度技术。在《DPDK技术栈在电信云中的最佳实践(一)》一文中,我们介绍过服务器的NUMA架构,其产生的主要原因就是解决服务器SMP架构扩展性能的问题。同样,在计算虚拟化中的CPU资源调度方面,也有基于服务器NUMA架构的调度技术,这就是Host NUMA和Guest NUMA技术,它们都是虚拟化软件技术。 Host NUMA主要提供CPU负载均衡机制,解决CPU资源分配不平衡引起的VM性能瓶颈问题,当启动VM时,Host NUMA根据当时主机内存和CPU负载,选择一个负载较轻的node放置该VM,使VM的CPU和内存资源分配在同一个node上。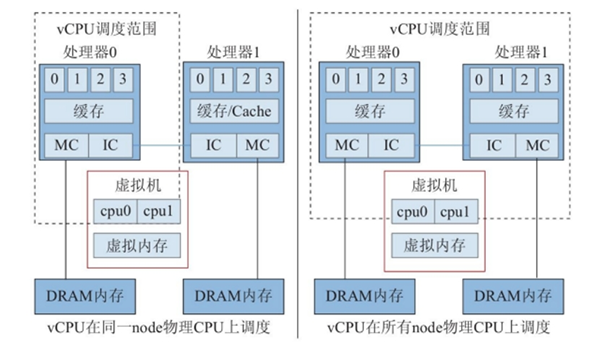 如上图左边所示,Host NUMA把VM的物理内存放置在一个node上,对VM的vCPU调度范围限制在同一个node的物理CPU上,并将VM的vCPU亲和性绑定在该node的物理CPU上。考虑到VM的CPU负载是动态变化,在初始放置的node上,node的CPU资源负载也会随之变化,这会导致某个node的CPU资源不足,而另一个node的CPU资源充足,在此情况下,Host NUMA会从CPU资源不足的node上选择VM,把VM的CPU资源分配在CPU资源充足的node上,从而动态实现node间的CPU负载均衡。Host NUMA保证VM访问本地物理内存,减少了内存访问延迟,可以提升VM性能,性能提升的幅度与VM虚拟机访问内存大小和频率相关。对于VM的vCPU个数超过node中CPU的核数时,如上图右边所示,Host NUMA把该VM的vCPU和内存均匀地放置在每个node 上,vCPU的调度范围为所有node的CPU。 如果用户绑定了VM的vCPU亲和性,Host NUMA特性根据用户的vCPU亲和性设置决定VM的放置,若绑定在一个node的CPU上,Host NUMA把VM的内存和CPU放置在一个node上,若绑定在多个node的CPU上,Host NUMA把VM的内存均匀分布在多个node 上,VM的vCPU在多个node的CPU上均衡调度。 Host NUMA技术的本质保证了VM访问本地物理内存,减少了内存访问延迟,可以提升VM性能,性能提升的幅度与VM访问内存大小和频率相关。Host NUMA主要应用于针对大规格、高性能虚拟机场景,适用Oracle、 SQL Server等关键应用。
如上图左边所示,Host NUMA把VM的物理内存放置在一个node上,对VM的vCPU调度范围限制在同一个node的物理CPU上,并将VM的vCPU亲和性绑定在该node的物理CPU上。考虑到VM的CPU负载是动态变化,在初始放置的node上,node的CPU资源负载也会随之变化,这会导致某个node的CPU资源不足,而另一个node的CPU资源充足,在此情况下,Host NUMA会从CPU资源不足的node上选择VM,把VM的CPU资源分配在CPU资源充足的node上,从而动态实现node间的CPU负载均衡。Host NUMA保证VM访问本地物理内存,减少了内存访问延迟,可以提升VM性能,性能提升的幅度与VM虚拟机访问内存大小和频率相关。对于VM的vCPU个数超过node中CPU的核数时,如上图右边所示,Host NUMA把该VM的vCPU和内存均匀地放置在每个node 上,vCPU的调度范围为所有node的CPU。 如果用户绑定了VM的vCPU亲和性,Host NUMA特性根据用户的vCPU亲和性设置决定VM的放置,若绑定在一个node的CPU上,Host NUMA把VM的内存和CPU放置在一个node上,若绑定在多个node的CPU上,Host NUMA把VM的内存均匀分布在多个node 上,VM的vCPU在多个node的CPU上均衡调度。 Host NUMA技术的本质保证了VM访问本地物理内存,减少了内存访问延迟,可以提升VM性能,性能提升的幅度与VM访问内存大小和频率相关。Host NUMA主要应用于针对大规格、高性能虚拟机场景,适用Oracle、 SQL Server等关键应用。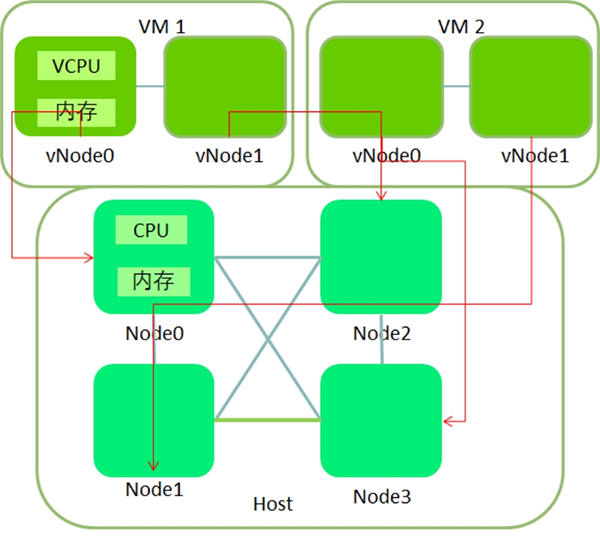 Guest NUMA如上图所示,能够使得虚拟机内部程序运行时针对NUMA结构进行优化,CPU会优先使用同一个Node上的内存,从而减小内存访问延时、提高访问效率,以此达到提升应用性能的目的。目前OS和应用都会有针对NUMA的优化,VMM通过向虚拟机呈现NUMA结构,使Guest OS及其内部应用识别Numa结构, CPU会优先使用同一个Node上的内存,减小内存访问延时、提高访问效率。 Guest NUMA技术的本质就是VMM保证NUMNA结构的透传,使虚拟机中的关键应用在NUMA方面的优化生效,减少了内存访问延迟,可以提升VM性能。Guest NUMA主要应用于虚拟机中应用程序减小内存访问延时、提高访问效率,以此达到提升应用性能的目的。
Guest NUMA如上图所示,能够使得虚拟机内部程序运行时针对NUMA结构进行优化,CPU会优先使用同一个Node上的内存,从而减小内存访问延时、提高访问效率,以此达到提升应用性能的目的。目前OS和应用都会有针对NUMA的优化,VMM通过向虚拟机呈现NUMA结构,使Guest OS及其内部应用识别Numa结构, CPU会优先使用同一个Node上的内存,减小内存访问延时、提高访问效率。 Guest NUMA技术的本质就是VMM保证NUMNA结构的透传,使虚拟机中的关键应用在NUMA方面的优化生效,减少了内存访问延迟,可以提升VM性能。Guest NUMA主要应用于虚拟机中应用程序减小内存访问延时、提高访问效率,以此达到提升应用性能的目的。(采编:www.znzbw.cn)